

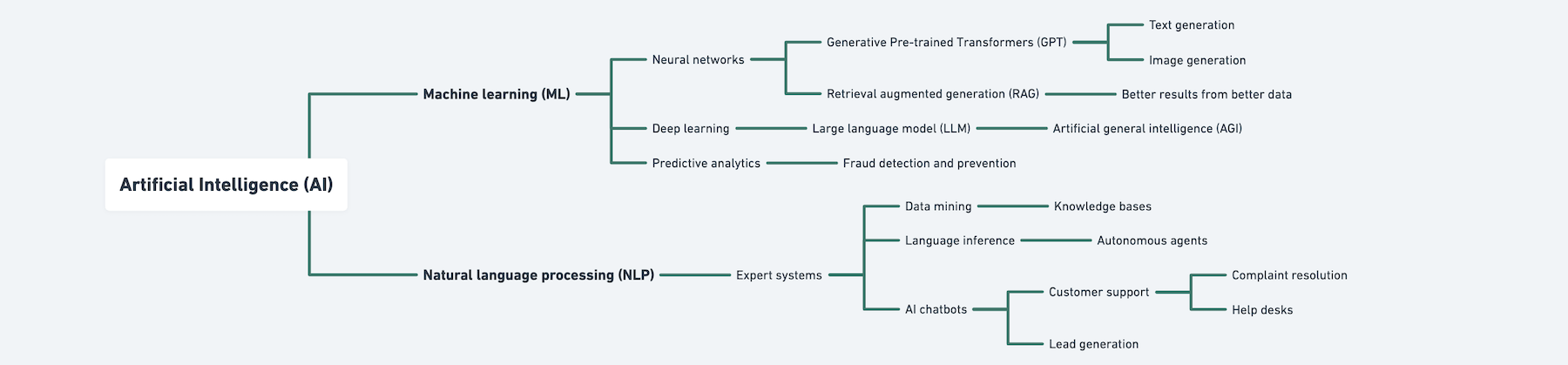
How we got here
The term “artificial intelligence” was coined in 1955 by John McCarthy in a Dartmouth workshop about thinking machines. The phrase “machine learning” was conceived in 1959 by Arthur Samuel in a speech about teaching machines to play chess better than the humans that programmed them.
This ability to learn is embodied in “neural networks” which for decades has played a quiet role in diverse fields from product recommendations to credit card fraud to facial recognition and more.
There have been many neural network architectures but notably, “The Transformer” is a game changing architecture introduced in 2017 by Google. Building upon that concept, OpenAI applied the pre-existing concept of “Generative Pre-training” to the Transformer architecture in 2018.
The generative pre-trained transformer (GPT) architecture is notable as a large language model (LLM) with the ability to adapt it’s language generation capability to topics on which it was not provided with training data.
To solve ever more complex problems and meet more diverse use cases, larger and larger LLMs, trained on many billions of parameters have resulted in an explosion of AI into nearly all corners of the modern world.
By the way, this is not meant to be a complete summary of AI. Other branches exist, including autonomous vehicles, robotics and computer vision. It’s a broad field.
Foundational concepts surrounding LLMs and generative AI
- You use an LLM by submitting a “prompt” and receiving a “response.”
- Training data, if not carefully chosen and prepared can give the LLM undesirable biases.
- LLMs work by performing “inference” which means creating a response by guessing what word should come next.
- Training a LLM takes significant computing power.
- Performing inference with a LLM takes significant computing power.
- “Prompt engineering” refers to the strategies used in authoring the prompt to generate a more desirable response. (See also “few-shot” and “chain of thought” prompting.)
- In a Q&A session with an LLM, contextual follow-up questions cannot exceed the “context window” which is the backwards looking memory of the LLM.
- Bigger LLMs often have larger context windows to enable more sophisticated prompt engineering and more meaningful dialog with the LLM.
- Larger context windows enable submitting relevant data along with the prompt to give the LLM the raw materials it can use to produce a superior prompt.
- “Retrieval augmented generation” (RAG) is a strategy to prepare a knowledge base to enable a “nearest-neighbor vector search” based on the prompt to retrieve and use the most ideal data in preparing the most accurate response.
- Preparing a knowledge base for vector searching requires extracting the text and creating “embeddings” which are vector representations of a chunk of text.
- A RAG system 1) stores embeddings in a “vector database,” 2) creates embeddings of the user prompt, 3) performs a vector search to retrieve the best data for the given prompt and finally 4) submits that data to the LLM along with the prompt to generate the response.
- RAG systems are only one example of the trend away from user typed prompts to software generated prompts. (See “Langchain,” agents, plugins and its growing ecosystem.)
- When doing inference, LLMs will frequently “hallucinate” by including incorrect or nonsensical words in their responses.
- Given the likelihood of hallucinations, LLM responses should be carefully reviewed, edited and fact checked before use.
- Text generation models and image generation models are being replaced with “multimodal LLMs” which can incorporate words, images and even software code in their responses.
- Some multimodal LLMs can accept words, images and code in user prompts.
John Knapp has significant experience harnessing LLMs and related technologies in RAG systems for the enterprise. Visit IncisiveLabs.com if you would like some help.
Last edit, 2023-10-24